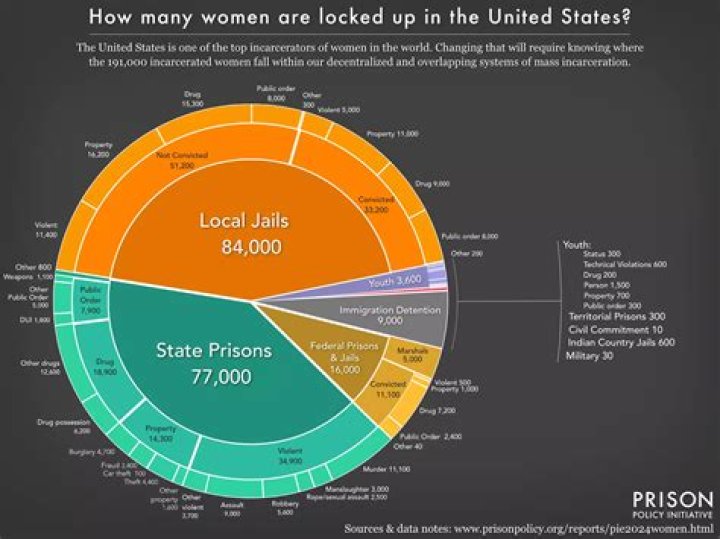
How many clustered indexes can you have
There can be only one clustered index per table, because the data rows themselves can be stored in only one order. The only time the data rows in a table are stored in sorted order is when the table contains a clustered index.
Can you have multiple clustered indexes?
It isn’t possible to create multiple clustered indexes for a single table. From the docs (emphasis mine): Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition.
Can you have multiple non clustered indexes?
SQL Server allows us to create multiple Non-clustered indexes, up to 999 Non-clustered indexes, on each table, with index IDs values assigned to each index starting from 2 for each partition used by the index, as you can find in the sys.
What is the maximum number of clustered indexes a table can have?
Clustered Index. A clustered index defines the order in which data is physically stored in a table. Table data can be sorted in only way, therefore, there can be only one clustered index per table.How many non clustered indexes can you have?
The maximum number of nonclustered indexes that can be created per table is 999. This includes any indexes created by PRIMARY KEY or UNIQUE constraints, but does not include XML indexes.
What is better clustered or nonclustered index?
If you want to select only the index value that is used to create and index, non-clustered indexes are faster. For example, if you have created an index on the “name” column and you want to select only the name, non-clustered indexes will quickly return the name.
Can you have a primary key and a clustered index?
A primary key is a unique index that is clustered by default. By default means that when you create a primary key, if the table is not clustered yet, the primary key will be created as a clustered unique index.
What is clustered and non clustered index?
A Clustered index is a type of index in which table records are physically reordered to match the index. A Non-Clustered index is a special type of index in which logical order of index does not match physical stored order of the rows on disk.Can I have too many indexes Why?
The reason that having to many indexes is a bad thing is that it dramatically increases the amount of writing that needs to be done to the table. This happens in a couple of different places. When a write happens the data first is logged to the transaction log.
Can we have both clustered and nonclustered index on table?Both clustered and nonclustered indexes can be unique. This means no two rows can have the same value for the index key. Otherwise, the index is not unique and multiple rows can share the same key value.
Article first time published onWhat is nonclustered index?
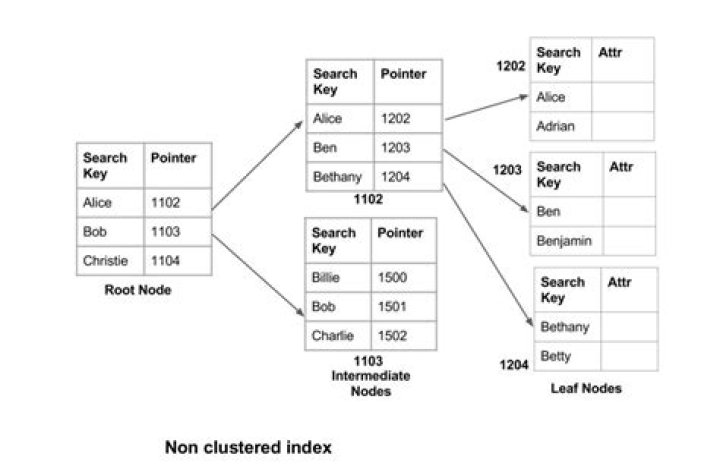
A non-clustered index (or regular b-tree index) is an index where the order of the rows does not match the physical order of the actual data. … In a non-clustered index, the leaf pages of the index do not contain any actual data, but instead contain pointers to the actual data.
Can we create a primary key with non-clustered index?
Primary Key can be Clustered or Non-clustered but it is a common best practice to create a Primary Key as Clustered Index. … Primary Key should be uniquely identifying column of the table and it should be NOT NULL.
What is clustered index?
Clustered indexes are indexes whose order of the rows in the data pages corresponds to the order of the rows in the index. … With clustered indexes, the database manager attempts to keep the data in the data pages in the same order as the corresponding keys in the index pages.
Does index take space in disk?
Does index take space in the disk? Explanation: Indexes take memory slots which are located on the disk.
How do I get rid of a non clustered index?
To drop a clustered or nonclustered index, issue a DROP INDEX command. When you do this, the metadata, statistics, and index pages are removed. If you drop a clustered index, the table will become a heap. Once an index has been dropped, it can’t be rebuilt – it must be created again.
Can I create clustered index on multiple columns?
SQL Server allows only one clustered index per table because a clustered index reorders the table, arranging the data according to the index key. … You can’t use a clustered index, but you can create an unclustered index on multiple columns and gain a nice performance increase.
Should all tables have a clustered index?
As a rule of thumb, every table should have a clustered index. Generally, but not always, the clustered index should be on a column that monotonically increases–such as an identity column, or some other column where the value is increasing–and is unique. … With few exceptions, every table should have a clustered index.
Can we create clustered index on varchar column?
Yes, you can create a clustered index on non-unique nullable varchar column.
Does a clustered index improve performance?
Effective Clustered Indexes can often improve the performance of many operations on a SQL Server table. … To be clear, having a non-clustered index along with the clustered index on the same columns will degrade performance of updates, inserts, and deletes, and it will take additional space on the disk.
Which indexing is better in SQL?
On the other hand, clustered indexes can provide a performance advantage when reading the table in index order. This allows SQL Server to better use read ahead reads, which are asymptotically faster than page-by-page reads. Also, a clustered index does not require uniqueness.
Are clustered indexes bad?
If such clustered index is created on a table with frequent inserts and updates, it can cause performance degradation. It’s not recommended to use the primary key as a clustered key without checking whether that is the optimal solution in you scenario first.
How many index is too much?
Sometimes, even just 5 indexes are too many. When you have a table where insert and delete speeds are absolutely critical, and select speeds don’t matter, then you can increase performance by cutting down on your indexes.
Do indexes slow down inserts?
1 Answer. Indexes and constraints will slow inserts because the cost of checking and maintaining those isn’t free. The overhead can only be determined with isolated performance testing.
When should indexes be avoided?
- Indexes should not be used on small tables.
- Tables that have frequent, large batch updates or insert operations.
- Indexes should not be used on columns that contain a high number of NULL values.
- Columns that are frequently manipulated should not be indexed.
Is B tree clustered index?
Also known as B-Tree index. The data is ordered in a logical manner in a non-clustered index. The rows can be stored physically in a different order than the columns in a non-clustered index. Therefore, the index is created and the data in the index is ordered logically by the columns of the index.
What is the advantage of the clustered index?
A clustered index is useful for range queries because the data is logically sorted on the key. You can move a table to another filegroup by recreating the clustered index on a different filegroup. You do not have to drop the table as you would to move a heap.
What is the difference between a clustering index and a secondary index?
Secondary Index − Secondary index may be generated from a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values. Clustering Index − Clustering index is defined on an ordered data file. The data file is ordered on a non-key field.
Which of the following is true about clustered index?
Que.Which one is true about clustered index?b.Clustered index is built by default on unique key columnsc.Clustered index is not built on unique key columnsd.None of the mentionedAnswer:Clustered index is built by default on unique key columns
What is secondary index?
A secondary index is a data structure that contains a subset of attributes from a table, along with an alternate key to support Query operations. You can retrieve data from the index using a Query , in much the same way as you use Query with a table.
How non-clustered index helps to fetch the data?
A non-clustered index helps you to creates a logical order for data rows and uses pointers for physical data files. Allows you to stores data pages in the leaf nodes of the index. This indexing method never stores data pages in the leaf nodes of the index.
Does nonclustered index allow duplicates?
Unique Non Cluster Index only accepts unique values. It does not accept duplicate values. After creating a unique Non Cluster Index, we cannot insert duplicate values in the table.