Which hive component is responsible for execution of Hive queries
The conjunction part of HiveQL process Engine and MapReduce is Hive Execution Engine. It processes the query and generates results same as MapReduce results.
What executes the Hive query?
Interface of the Hive such as Command Line or Web user interface delivers query to the driver to execute. In this, UI calls the execute interface to the driver such as ODBC or JDBC. Driver designs a session handle for the query and transfer the query to the compiler to make execution plan.
What are the components used in Hive query processor?
- Parse and Semantic Analysis (ql/parse)
- Metadata Layer (ql/metadata)
- Type Interfaces (ql/typeinfo)
- Sessions (ql/session)
- Map/Reduce Execution Engine (ql/exec)
- Plan Components (ql/plan)
- Hive Function Framework (ql/udf)
- Tools (ql/tools)
Which component is responsible for execution and optimization of queries?
In a relational database system the query processor is the module responsible for executing database queries. The query processor receives as input queries in the form of SQL text, parses and optimizes them, and completes their execution by employing specific data access methods and database operator implementations.Where is query execution time in Hive?
Click on Tez View underneath Hive View button will display the execution time for job. Search for your application ID then you can get all logs and execution times.
Which of the following is components of Hadoop?
There are four major elements of Hadoop i.e. HDFS, MapReduce, YARN, and Hadoop Common. Most of the tools or solutions are used to supplement or support these major elements. All these tools work collectively to provide services such as absorption, analysis, storage and maintenance of data etc.
What is the default execution engine in Hive?
Chooses execution engine. Options are: mr (Map Reduce, default), tez (Tez execution, for Hadoop 2 only), or spark (Spark execution, for Hive 1.1. 0 onward). While mr remains the default engine for historical reasons, it is itself a historical engine and is deprecated in the Hive 2 line (HIVE-12300).
Which component of query processor is responsible for translating DML query to relational algebra expression?
The parser creates a tree of the query, known as ‘parse-tree. ‘ Further, translate it into the form of relational algebra. With this, it evenly replaces all the use of the views when used in the query.What is responsible for compilation optimization and execution of Hive queries?
The user interacts with the Hive through the user interface by submitting Hive queries. The driver passes the Hive query to the compiler. The compiler generates the execution plan. The Execution engine executes the plan.
What is the role of query processor in the execution of SQL queries?The query processor is the subcomponent of the data server that processes SQL requests. The SQL requests can access a single database or file system or reference multiple types of databases or file systems. … Accesses and joins information from multiple data sources and performs updates to multiple data sources.
Article first time published onWhat is Hive query processor?
17) Mention what Hive query processor does? Hive query processor convert graph of MapReduce jobs with the execution time framework. So that the jobs can be executed in the order of dependencies.
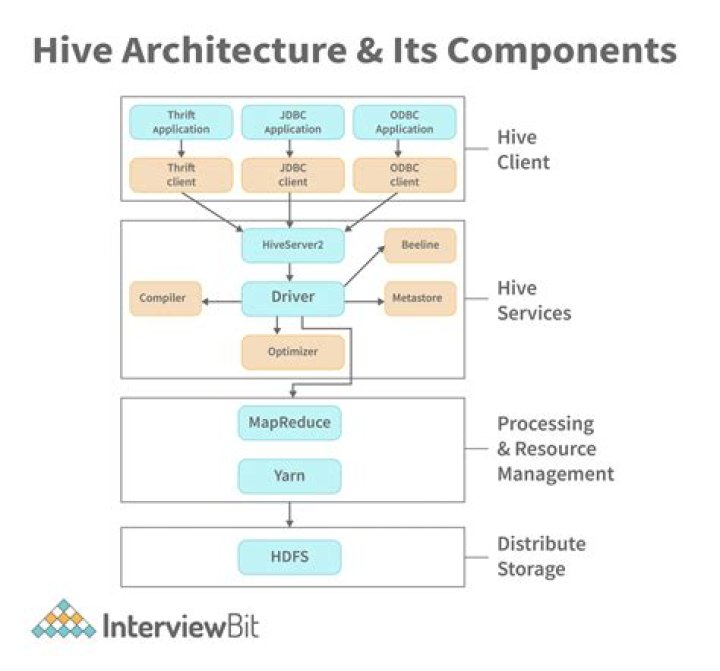
What is Hive architecture?
Architecture of Hive Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. … The conjunction part of HiveQL process Engine and MapReduce is Hive Execution Engine. Execution engine processes the query and generates results as same as MapReduce results.
What is the functionality of query processor in Apache Hive?
Query Processor (trunk/ql) – This component implements the processing framework for converting SQL to a graph of map/reduce jobs and the execution time framework to run those jobs in the order of dependencies.
How do I reduce Hive query execution time?
- Use Tez Engine. Apache Tez Engine is an extensible framework for building high-performance batch processing and interactive data processing. …
- Use Vectorization. …
- Use ORCFile. …
- Use Partitioning. …
- Use Bucketing. …
- Cost-Based Query Optimization.
What is an execution engine?
The execution engine is the Central Component of the java virtual machine(JVM). … Each thread of a running application is a distinct instance of the virtual machine’s execution engine. Execution engine executes the byte code which is assigned to the run time data areas in JVM via class loader.
What is Spark execution engine?
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching and optimized query execution for fast queries against data of any size. Simply put, Spark is a fast and general engine for large-scale data processing.
What is execution engine in Hadoop?
Description. The Execution Engine for Apache Hadoop services integrates the Watson Studio service with your remote Apache Hadoop cluster. Data scientists can use this service for the following tasks: … Cleanse and shape remote Hadoop data with Data Refinery. Run Data Refinery and jobs on the Hadoop Spark cluster.
Which component is responsible for planning and execution of a single job in Hadoop?
The YARN or Yet Another Resource Negotiator is the update to Hadoop since its second version. It is responsible for Resource management and Job Scheduling.
Which component coordinates between all components of Hadoop?
Zookeeper It coordinates between the various services in the Hadoop ecosystem. It coordinates with the various features in a distributed environment. It saves a lot of time by performing synchronization, configuration maintenance, grouping, and naming.
Which of the following components is responsible for planning and execution of a single job in Hadoop architecture?
It allocates resources to applications based on the needs. NodeManager: NodeManager is installed on every DataNode and it is responsible for the execution of the task on every single Data Node.
What are the components of pig execution environment?
- Parser. Initially the Pig Scripts are handled by the Parser. …
- Optimizer. The logical plan (DAG) is passed to the logical optimizer, which carries out the logical optimizations such as projection and pushdown.
- Compiler. …
- Execution engine. …
- Atom. …
- Tuple. …
- Bag. …
- Map.
How do I find hive execution plan?
Hive uses a cost-based optimizer to determine the best method for scan and join operations, join order, and aggregate operations. You can use the Apache Hive EXPLAIN command to display the actual execution plan that Hive query engine generates and uses while executing any query in the Hadoop ecosystem.
What does hive do in Hadoop?
Hive allows users to read, write, and manage petabytes of data using SQL. Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets. As a result, Hive is closely integrated with Hadoop, and is designed to work quickly on petabytes of data.
What are the steps involved in query processing?
- Step 1: Parsing. …
- Step 2: Translation. …
- Step 3: Optimizer. …
- Step 4: Execution Plan. …
- Step 5: Evaluation.
What does a query processor do in semantic checking?
– Checks whether all the relations mentioned under the FROM clause in the SQL statement are from the database the user is referenced. – Checks all the attribute values and also checks whether they exist in a particular relation that is specified in the query.
What is query process?
Definition. Query processing denotes the compilation and execution of a query specification usually expressed in a declarative database query language such as the structured query language (SQL). Query processing consists of a compile-time phase and a runtime phase.
Which component of the relational DBMS is responsible for generating an execution plan?
QL Server relational engine – responsible for generating the query execution plan. SQL Server storage engine – gets query execution plan as input and takes action upon it to return the desired result.
How a SQL query is executed?
- Getting Data (From, Join)
- Row Filter (Where)
- Grouping (Group by)
- Group Filter (Having)
- Return Expressions (Select)
- Order & Paging (Order by & Limit / Offset)
How SQL query is executed internally?
- 1) Row filtering – Phase 1: Row filtering – phase 1 are done by FROM, WHERE , GROUP BY , HAVING clause.
- 2) Column filtering: Columns are filtered by SELECT clause.
- 3) Row filtering – Phase 2: Row filtering – phase 2 are done by DISTINCT , ORDER BY , LIMIT clause.
What is yarn architecture?
YARN stands for “Yet Another Resource Negotiator“. … YARN architecture basically separates resource management layer from the processing layer. In Hadoop 1.0 version, the responsibility of Job tracker is split between the resource manager and application manager.
What is the file format of hive?
File FormatDescriptionProfileTextFileFlat file with data in comma-, tab-, or space-separated value format or JSON notation.Hive, HiveTextSequenceFileFlat file consisting of binary key/value pairs.HiveRCFileRecord columnar data consisting of binary key/value pairs; high row compression rate.Hive, HiveRC


